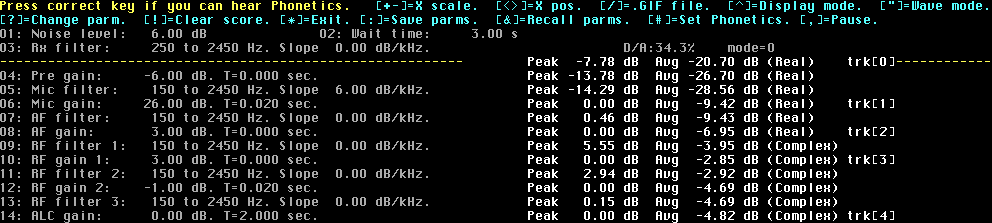
Fig 1. The voicelab screen.
Introduction.All voice modulation methods have an amplitude limit, a level that must not be exceeded. This is valid for FM and SSB as well as for AM. It is of course possible to set the microphone gain low enough to make the largest amplitude peaks that occur when speaking into the microphone low enough to never exceed the limit. Doing so will provide the best sound quality, but only when the RF signal is strong. The average amplitude from the microphone would be far below the limit nearly all the time and the transmission channel would be poorly used.It is well known from amateur literature that an RF clipper is much better than an audio clipper. This is not quite true however, the RF clipper is better but the difference is small as long as the clipping is not harder than necessary for good intelligibility at low S/N ratios. The drawback of audio clipping is often illustrated with a sine-wave as the input waveform like this: Let us assume that the passband is 0.2 to 2.4 kHz and that the signal from the microphone is 300Hz. An audio clipper will convert the waveform towards a square-wave that contains odd harmonics. The frequencies 900 Hz, 1.5 kHz and 2.1 kHz will fall within the passband and make the sound that comes out of the loudspeaker at the receive site very different from the original sine-wave. An RF clipper will of course also convert the sine-wave which is present at e.g. 10.7 MHz to a square-wave but the overtones at 32.1 MHz and higher will not pass through the filters, only the original sine-wave will remain and be transmitted so the output from the loudspeaker at the receive side will be exactly the original sine-wave (assuming a correct BFO setting). The only effect of RF clipping to a sine-wave is to reduce the amplitude to make it fit the power limitations of the power amplifier. The argument that a sine-wave will not be distorted by an RF clipper may sound convincing, but it is not really a valid argument why RF clipping is better than audio clipping. The purpose of the speech processor is to distort the waveform. The human voice is not a sine-wave. If it were, an audio AGC would be the perfect speech processing, fully equivalent to RF clipping. With short pulses sent into the microphone it does not make any difference whether clipping is made at AF or RF. Likewise, if two signals at say 800 and 900 Hz were sent into the microphone input, the third order intermodulation at 700 and 1000 Hz would be the same for RF and audio clipping. One could argue that the human voice is much more like a series of pulses than a sinewave and that the difference between AF and RF clipping therefore should be small. The only way to really know is to make tests with a real voice signal. I have done such tests some 30 years ago and nobody was able to say whether I was using RF or AF clipping. I did these tests at marginal signal levels only - for strong signals it is easy to hear the difference. Transmit mode in LinradAdding transmit capabilities to Linrad is a natural extention. With Linrad-01.25 some small first steps are taken in this direction.A high performance Linrad system typically uses two soundcards, a high speed high performance card for the input to provide a large bandwidth and a high dynamic range. For loudspeaker output another soundcard running at a low sampling speed is used. It is natural to use the low speed, low grade soundcard for microphone input and the high performance wideband card for transmitter output to generate a radio frequency signal in the range 25 to 40 kHz or so. Such a signal can then be converted to higher radio frequencies with some arrangement of frequency mixers. In case Linrad is used to process the output of an ordinary receiver one typically uses the same soundcard for input and output so for use of the Linrad transmit routines it will be necessary to add a second soundcard. The Linrad transmit routines will then serve as a speech processor, CW keyer or encoder for various digital modes to produce an audio signal that fits the microphone input of an ordinary SSB transmitter. Speech processing is a natural first step towards implementing transmitter functions in Linrad. Besides setup routines for microphone and transmitter output, Linrad-01.27 contains routines to evaluate intelligibility of processed voice signals at low S/N. (Note that Linrad versions 01.25 and 01.26 contain a bug that makes the simulations in these versions incorrect.) The purpose of including these routines is to try to get some feedback. What is the optimum speech processing at very low S/N? Does it depend on the individual characteristics of the operators voice? As shown below, speech processing is not very critical. Linrad allows many different ways of processing the signal but as it turns out, the difference in intelligibility is very small. Not unexpectedly it follows closely to the average power. The complications in speech processing occur because of repeaking. When a flattened waveform is run through a filter that removes part of the signal energy, the signal at the other side of the filter is no longer flat. This effect will typically degrade the peak to average power by 2 or 3 dB when one sideband is removed by an SSB filter. This is the real reason why RF clippers are a little better than audio clippers. Repeaking also degrades the peak to average power ratio of a signal that is limited by an RF clipper. The filter necessary behind the RF clipper will remove the intermodulation products (splatter) that is outside the passband and this will typically degrade the peak to average power by 2 dB or so. Running VoicelabTo use the speech processing simulation in Linrad you need a computer that allows two independent input channels and two independent output channels running simultaneously. This is because the setup routine looks for hardware that can be used while the receiver is running.Select V=Tx mode setup on the Linrad main menu. If you do not have an acceptable par_tx file you will be prompted to the setup routine which will work only if you have devices for simultaneous transmit and receive. If your setup file is ok you will come to a menu where you can select A=Speech Processor Lab. Here you can record and edit phonetics for each letter and number on the keyboard. You can also download a complete set of phonetics here: voicelab.bin ( 4421956 bytes, 48kHz sampling speed) This file will work only if your par_tx file is set for A/D speed=48000 and if your loudspeaker output (the one used in receiver mode) is capable of running mono at 48 kHz. Setting a very high sampling speed like this is not recommended for the Linrad transmit routines, it is only for simulations with voicelab. As it turns out, the high sampling speed is completely useless. It allows things like setting a pre-emphasis of +16 dB/kHz over 15 kHz bandwidth, then do audio clipping, then run the clipped signal through a filter with a de-emphasis of -10 dB/kHz. Very short impulses would be treated very differently, they would be clipped and removed similarly to the operation of a wideband noise blanker. The screen that comes up when you press B=Evaluate speech processing looks like this: |
Press the ? key, then one of the line numbers to change
a processing parameter on the corresponding line.
Listen to the noise and the Phonetics in the noise and
press the correct key on the keyboard.
The last two lines on the screen will show error statistics
and any mistake you make.
Change the noise level until your statistics has degraded to
somewhere between 50 and 75 %.
You can change the processing parameters to evaluate what
processing will give the best intelligibility at very poor
S/N ratios.
See below for details.
You can also reduce the noise to for example -40dB and listen
to the distorted voice and decide if the distortion is acceptable
for use at normal signal levels.
Preliminary resultsRunning the test for 100 times on six different sets of processing parameters has given the result shown in table 1. |
Type of Peak to Parameter Fraction of correct copy at noise level processing average file -4dB -2dB 0dB +2dB +4dB +6dB +8dB +10dB +12dB Nothing 12.8dB voicepar1.bin 93% 87% 71% 45% - - - - - AF AGC,20dB 5.0dB voicepar2.bin - - 100% 100% 100% 83% 67% - - AF clipper,20dB 4.6dB voicepar3.bin - - - - 98% 96% 87% 68% - RF clipper,20dB 2.4dB voicepar4.bin - - - - - 100% 100% 87% 64% Everything 1.8dB voicepar5.bin - - - - - 100% 99% 89% 70% RF clipper,40dB 3.8dB voicepar6.bin - - - - - 100% 100% 88% 66%Table 1. Intelligibility of compressed voice Phonetics at very low S/N. The peak to average ratio is for Z (zulu). |
The results of table 1 are shown graphically in fig. 2.
The processing gains are:
|
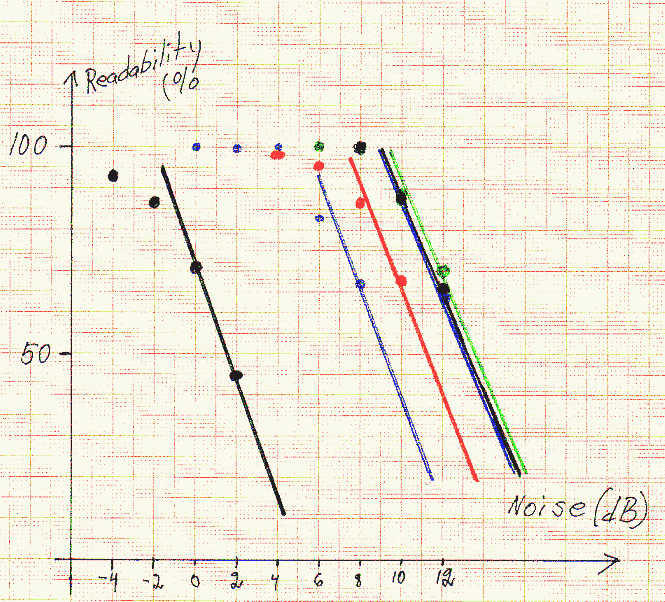
Fig 2. Intelligibility at different noise levels for different types of speech processing. The data is from table 1. |
|
The results presented here are based on a limited test. In case you find this interesting and want to make your own experiments with your own voice, download Linrad-01.27 (or later) and go ahead. What do the voicelab parameters mean?The simulation is a long chain of processing steps. The idea is to allow variuos kinds of experiments to try to find out if there are some special features that would be valuable to actually include in the Linrad tx software.The Phonetics as fetched from the voicelab.bin file does not have a constant peak amplitude. If you make your own file you can deliberately make the signal level slightly different for different Phonetics to allow the simulation to take reasonable variations in speech amplitude into account. For C (charlie) the peak power is -7.78 dB and the average power is -20.70 dB as you can see in figure 1 on the line with yellow hyphens. This is the input signal and it is recorded at 48000 samples per second. The microphone used does not give much response above 6 kHz so the signal is already subjected to some low pass filtering. Figure 1 is saved while Linrad was processing C (charlie) using the parameters in voicepar5.bin The first processing step (Pre gain) is an amplifier and AGC/limiter that will limit the output to 0 dB peak power. The gain is set to -6 dB in order to ensure that the AGC/limiter is inactive for all Phonetics in voicelab.bin. The second processing step is an audio filter. The first filter , the Mic filter, may be set for a large bandwidth and with a positive slope that will amplify high frequencies more. In case that is done, transients in the input signal will become shorter and higher in amplitude and the clipper that follows in the second step can remove various kinds of pulses without affecting the voice signal much. With the parameters shown in fig. 1, the Mic filter is a filter that has a bandwidth of 2.2 kHz with a pre-emphasis (slope) of 6dB/kHz. This filter causes a loss of 1.86 dB in the average power, but the peak power is reduced only by 0.51 dB. Pre-emphasis tends to make the voice signal spectrum flatter so it degrades the peak to average power ratio. The third step is an amplifier and AGC/limiter operating on the filtered microphone signal. The gain is set to 26 dB so the signal reaching the limiter is 20 dB above the original microphone signal. Since the time constant is positive, an AGC with fast attack and slow release is used. The release time is 20 milliseconds only so the mic AGC actually gives some speech compression Note that the peak level after the AGC/clipper is 0.00 dB. As soon as AGC is active at any point of the waveform, the peak power becomes 0.00 dB. The peak to average power ratio is decreased from 14.27 to 9.42 dB. The fourth step is again a filter. Because of the very fast attack and decay times of the AGC, there is 0.46 dB of repeaking. This filter has the same bandwidth as the previous filter, but the modulation imposed on the signal by the AGC has created some signal energy outside the passband that is removed in this step. Note that repeaking increases the peak power while it leaves the average power essentially unchanged. The fifth stage is an AF amplifier with 3 dB gain followed by an audio clipper. The input signal is only 3.46 dB above the threshold so the corners generated are not very sharp and therefore the amount of energy produced outside the desired passband is not quite as high as if the audio processing had been 23 dB of audio clipping. Step 6 is conversion to RF folloved by an RF filter. Removing one sideband and limiting the bandwidth again to 2.3 kHz degrades the peak to average power from 6.95 dB to 9.50 dB from the AF limiter to the filtered SSB signal. Step 7 is an RF amplifier and RF clipper. 3 dB gain plus 5.55 dB of repeaking means that this RF clipper operates at 8.55 dB compression in fig. 1. At the output of this RF clipper the peak to average power ratio is 2.85 dB only. Step 8 is again a filter. At very high compression levels like this, repeaking is a severe problem and despite the modest clipping introduced in the previous step, repeaking degrades the peak to average power ratio to 5.86 dB. Step 9 is a 1 dB attenuator followed by a fast attack, fast release RF AGC. Since the gain reduction needed by the AGC is only 1.94 dB this AGC will not increase the bandwidth much even though the time constant is as short as 20 milliseconds (50 Hz) Step 10 is again a filter. Repeaking amounts to 0.15 dB only. Step 11 is a TGC (transmit gain control). This is an AGC with fast attack and slow release (2 seconds). The last step is above the yellow hyphens. It is the addition of random noise at the full sampling speed (48kHz) with a gaussian distribution and an average power of 1.00 (0 dB) followed by a filter that simulates the filter in the receiver. How to set the filters should be self explanatory as well as how to set the gain. The gain block, the AGC(ALC) or limiter always maximises the output waveform at 0 dB (1.00) but it can be done in three different ways: 1: T=0 => Use a simple limiter at 1.00. 2: T>0 => Use AGC with fast attack and T as the release time. 3: T<0 => Use a soft clipper. A function that bends the curve gradually while preventing it from ever going above 1.00. When T goes towards zero, the soft clipper goes towards the simple limiter. As a preliminary conclusion it seems to be enough to do the following processing steps in the Linrad transmit package: 1. Mic filter with pre-emphasis. 2. Audio AGC. 3. RF clipper. The operation would be controlled by 5 parameters: 1. Lowest frequency. (default 200 Hz) 2. Highest frequency. (default 2400 Hz) 3. Amount of pre-emphasis (default +6dB/kHz or 6dB/octave) 4. Audio AGC range (default 10 dB) 5. RF clipping level (default 20 dB) The user would be allowed to set these parameters in several combinations of his own. Narrower bandwidth will improve quite a bit if the station at the other end has to use a narrower bandwidth to avoid qrm. A much wider bandwidth will improve intelligibility on 144 MHz aurora if the station at the other end is able to open up the bandwidth. The results from experiments with speech compression have been published in DUBUS 4 2005 This article gives some more details that are aimet at explaining the observations. |