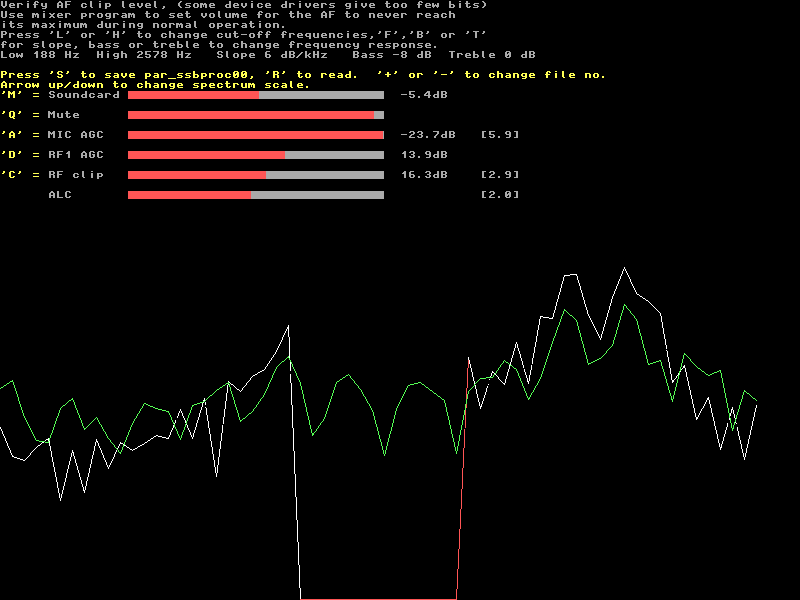
Overwiev.The transmit side of Linrad reads the audio from a soundcard. Typically the same low speed soundcard that is used for loudspeaker output will be used for microphone input. The input is treated in blocks that extend over about 10 to 20 milliseconds. When such a block is moved to the frequency domain with an FFT, each bin corresponds to about 50 to 100 Hz but since a sine squared window is used, the transform resolution is typically 100 to 200 Hz.Linrad uses several transformations to and back from the frequency domain. This page describes Linrad-02.36 which is the first version of the Linrad speech processor. Click here PRACTICAL to skip the detailed descriptions and go directly to sound files and power vs time graphs. Setup.By pressing "V", then "C" the user gets to the Tx setup routine. In case par_ssbproc00 does not yet exist the user is first prompted for selection of soundcards for Tx input and Tx output. In case the question "Enable Tx while running receive modes" is answered with "Y", Linrad will run the transmit side while the normal receiving goes on in SSB mode.In Linrad-02.36 the setup screen looks like figure 1. Here "AAAAA" is sent into the microphone and parameters are set for "agressive compression". |
|
|
|
Fig 1. The setup screen of the speech processor with "AAAAA" into the microphone input. The speech processor parameters are grouped into groups belonging to different functional blocks of the speech processing procedure. In figure 1 the block "M = Soundcard" is selected and the text on top of the screen describes the parameters and how to change them. There are several horizontal bar graphs. They all show the amount of activity in the processing step it belongs to. The processing steps of the speech processor are cascaded and it is a good idea to set the parameters in the order of the processing steps. I.e. start with "Soundcard", then "Mute" and so on as described below. Soundcard.First of all, the microphone and the soundcard have to match reasonably well. The bar graph on the "Soundcard" line shows the amplitude of the raw data from the soundcard. The input routine reads 16 bit data from the device selected by the user. The bar graph assumes that the range really is 16 bits, from -32768 to +32767. In real life this might not be true. It is a good idea to verify that the soundcard does not distort the signal by clipping it at some lower level. This is easily done with an audio generator. Just set a frequency at the low side of the passband and check how high you can go. If the harmonics increase dramatically, the level is too high.Figure 2 shows the setup screen with a 240 Hz tone into the microphone input of a "Creative Audio PCI97 (ES1371) (rev 6)" soundcard with the drive routines of OSS 4.0. In figure 3 the signal level is increased by 10 dB. Surely one would expect some saturation, but not to the extent visible in figure 3. This particular soundcard saturates 2.9 dB below the the expected level as can be seen on the sharp increase of the overtone content of the microphone signal seen by Linrad. (More below.) |
|
|
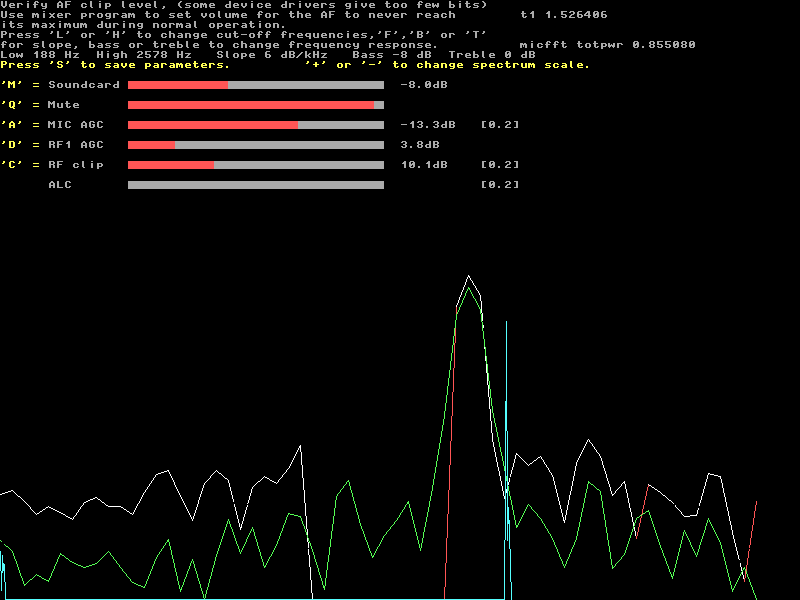
Fig 2. An audio generator sending 240 Hz into the microphone input of an ES1371 soundcard. |
|
|
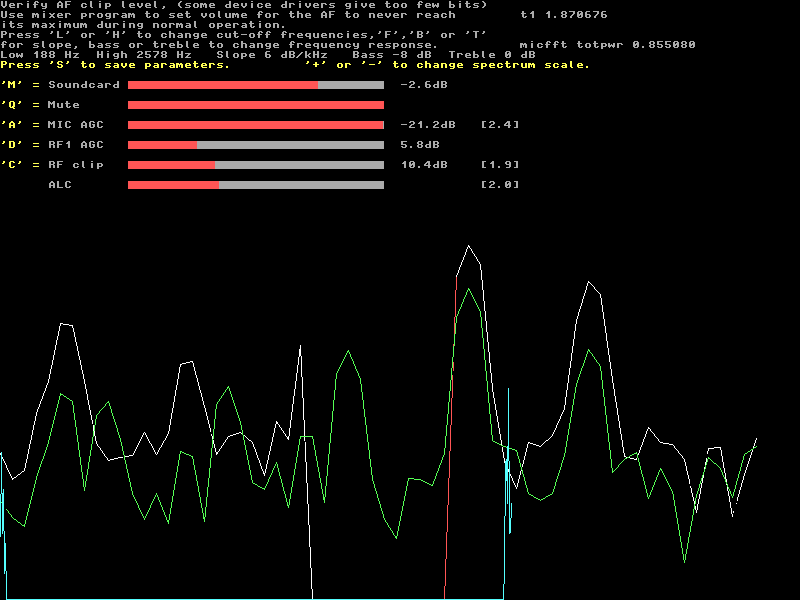
Fig 3. An audio generator sending 240 Hz into the microphone input of an ES1371 soundcard. The level is 10 dB higher as compared to figure 2. The first adjustment is to set the volume of the mixer program for a suitable peak amplitude of the voice signal from the microphone. Possibly an attenuator or amplifier should be added. The bar graph on the soundcard line ranges 20 dB and it is a good idea to put the loudest voice signal at a level that is below saturation, but visible in the bar graph. The next adjustment is to set the microphone filters. Press 'M' to get into "Soundcard" mode. (It is the default mode.) The first processing block is a fourier transform at whatever number of points that corresponds to about 10 to 20 milliseconds of data at the soundcard sampling speed. By multiplying this transform with the filter function specified by the bass, treble and slope parameters one can adjust the tone to suit ones own voice and microphone. All transform bins outside the low and high cut-off frequencies are set to zero. There is no need to retain more bins than required for the desired bandwidth. The white (and partly red) curve in figures 1 to 3 shows the spectrum of the microphone signal. The passband is from 188 to 2578 Hz so the passband center is at 1383 Hz. In the transforms, the passband center is placed at F=0 which is the first point at the left side of the screen. Frequencies below the center are negative and they occur at the right hand side of the spectrum. The tone generator at 240 Hz is at -1143 Hz near the center at the right hand side of figures 2 and 3. The third harmonic, 720 Hz occurs at -663 Hz, halfway between the fundamental and the spectrum end. Very strong in figure 3. The ES1371 soundcard only supports 48 kHz so the microphone FFT is of size 512 (1024 input points in real format to produce 512 complex output bins.) The total time spanned by one transform is 21 milliseconds. The passband from 188 to 2578 Hz is represented by the bins 4 to 55 out of the 512 ones in the spectrum that covers 24 kHz. By shifting these bins 30 points downwards, they will move to 486 to 511 (negative frequencies) and 0 to 25 (positive frequencies). The range 26 to 485 is all zero and will not contribute to the output when the back transform is taken. With only 50 valid points the there is no need for more than 64 points in the transform. Those points are from 38 to 63 (negative frequencies and from 0 to 25 (positive frequencies.) Figures 1 to 3 show the filtered microphone input in 63 points like this. The center region, bins 26 to 37 are outside the desired passband. Mute.Press 'Q' to enter the "Mute" mode. Muting is done in two steps. First all bins of the microphone FFT that are below the minimum value specified by the frequency domain threshold are cleared. The summed power of the surviving bins is then compared to the time domain threshold and the entire transform is cleared in case the total power is too low. The total power of the entire transform is the same in the time domain as in the frequency domain and in the actual Linrad code there is just a flag saying that zeroes should be inserted rather than a backwards transform.The purpose of muting is to allow reception during short gaps in the speech. One can then hear immediately if something happens on the frequency. The bar graph on the "Mute" line shows the percentage of surviving bins in the muting process. MIC AGC.Press 'A' to enter the "MIC AGC" mode. The purpose of an aggressive speech processor is to make the average power as close as possible to the peak power and to mute the transmitter and listen when the voice is below a threshold. Obviously the waveform must be distorted to accomplish this goal.The operator might change his voice level or the distance to the microphone. To compensate for that, Linrad has a microphone AGC that scales each transform that has survived the muting process to a constant average power. The muting thresholds are adjusted according to the AGC gain because the purpose of the AGC is to provide the same output even if the operator changes the microphone position a bit. This way the muting threshold stays at a fixed position relative to the current level of the voice signal. The microphone AGC has a time constant, but it is limited to 20 dB. Signals above that are considered to not be human voice and will not be remembered from transform to transform. Set the mic volume for the "MIC AGC" bar graph to stay within range for your normal voice operation. The time constant should be shorter than the time constant by which you move the microphone. The number within [] on the "MIC AGC" line is the peak to average power ratio at the output of the processing step. (5.3 dB in figure 1.) RF1 AGC.Press 'D' to enter the "RF1 AGC" mode. Setting the average power of each transform to a constant level is not quite correct. It is possible to set some gain and have an AGC in the time domain that will make the peak power constant instead.RF clip.Press 'C' to enter the "RF clip" mode. The signal already has a good average power due to AGC action so there is no need to clip the amplitude very hard.ALCThe RF clipper provides a very good peak to average power ratio, but it does that by introducing intermodulation products that are outside the desired passband. When the signal components outside the passband are filtered out, the peak power increases while the average power decreases. The phenomenon is known as "repeaking".The purpose of the ALC is to continuously adjust the gain to keep the peak power within range. The voltage that controls the gain is the output from a fast attack, slow release detector in conventional SSB transmitters. Since gain variation is the same as amplitude modulation, conventional transmitters produce wideband pulses each time the fast attack detector makes a jump. The Linrad ALC uses a bidirectional fast attack, slow release detector. This way the waveform by which the signal is modulated contains very little wideband energy and the spectral broadening due to the ALC is negligible. Other processesSince tx input and tx output belong to different soundcards, there is a fractional resampler that keeps the time delay through the speech processor constant.The resampler has to run on an oversampled time domain function and therefore the transform size is increased before the resampler. The final output may run at a much higher rate than the resampler. The conversion is made with yet another FFT. Practical results.Figure 4 shows the ITU phonetics (Alfa, Bravo, Charlie,....) Received at 2.5 MHz with the WSE converters and a Pentium III computer. The signal is generated by a Pentium IV that sends its output to a TX2500 unit. These were the processing parameters par_ssbproc00 |
|
|
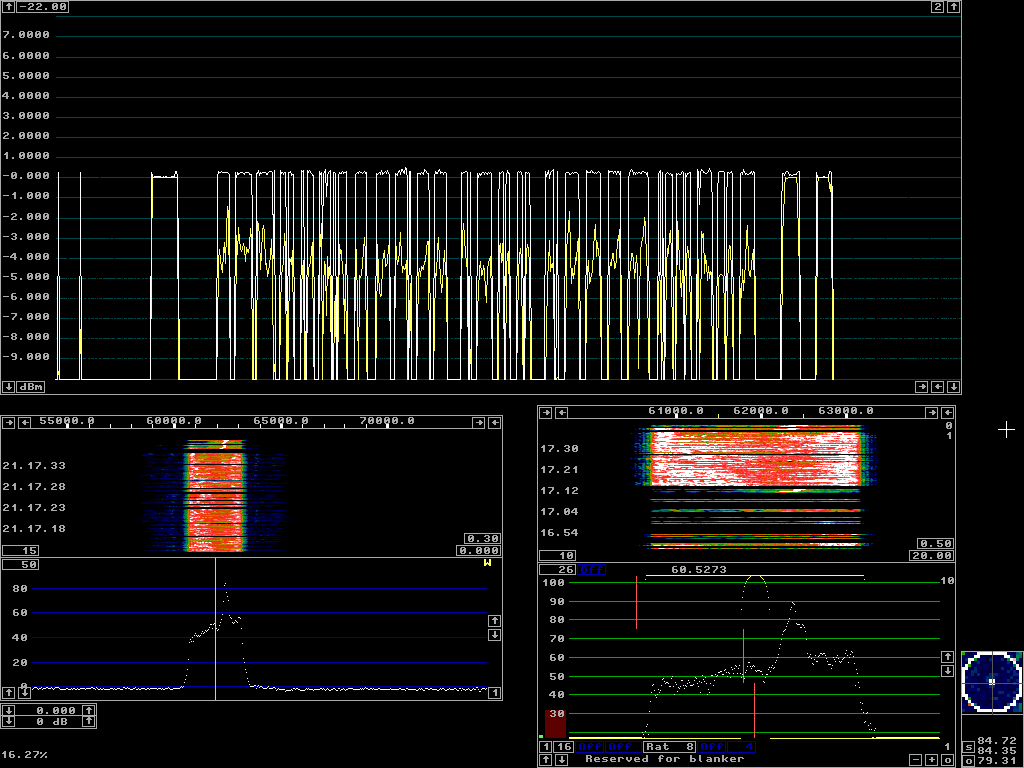
Fig 4. Phonetics generated by the Linrad speech processor and received at 2.5 MHz on another computer. The clipping is about 16 dB. The peak power is at 0 dBm on the S-meter graph. There is about 0.3 dB of re-peaking which can clearly be seen at the beginning and at the end where I was whistling into the microphone. At the end the first whistling was while breathing outwards causing some noise and about 0.3 dB extra peak power. The last time as well as at the beginning of the sequence I was whistling while breathing inwards. Then peak power and average power are identical. The average power is about 4 dB below the peak power. The sequence of phonetics shown in figure 4 was recorded to this file abc1.wav (The yellow W in the main spectrum is an indication of an on-going .WAV recording in Linrad.) The aggressive processing parameters give a distorted audio which is not optimum unless the signal is very weak and difficult to copy due to noise. Under normal operation one should set less RF clipping to get a less distorted signal, although at slightly less average power output. Figure 5 and this audio file abc2.wav show average power and sound quality at a modest clipping level of about 5 dB and less active microphone AGC. The cost for the lower distortion is about 3dB in output power on a system that is limited by peak power. The processing parameters par_ssbproc01 were used to produce figure 5 and abc2.wav. |
|
|
Fig 5. Phonetics generated by the Linrad speech processor and received at 2.5 MHz on another computer. The clipping is about 5 dB. While figure 5 was produced on the Pentium III computer, the Pentium IV was running in SSB receive mode showing a screen like figure 6. The frequency was set to 12 kHz in the transmit control window and the processing parameter file was set to 0 to use the processing parameters contained in par_ssbproc00. |

|
|
Fig 6. Here both the transmitter and the receiver are running on a 2.7GHz Pentium IV. Switching off the transmitter reduces the CPU load to about 11%. |